Android携帯(HT-03A)搭載フォントは JIS X 0213 未対応
先月(2009年12月)に、Android 携帯の HT-03A (台湾の HTC 製) を購入した。今のところ(開発用機器を除くと)日本で唯一の Android 携帯なのだが、本体価格は投げ売り状態で、池袋の量販店では0円か1円かという有様だった。また、昨年末から NTT ドコモが、スマートフォン向けのキャンペーンや新料金プランを相次いで実施している(特に「タイプシンプル バリュー」は店員が案内しない場合もあるので要チェック)。他に乗り換えるなどして全然使わなくなっても、不要なオプション、保険、さらにパケット定額対象のプロバイダ契約も止めれば、月々の支払いを800円以下に抑えられる。2年後の契約切れまで使い切らなくてもさほど負担にはならないと思い、購入に至った。いろんな機能を試したり、Android アプリケーション作成に挑戦してみたり、まあそれなりに楽しめるオモチャである。
そしてついつい、改定常用漢字表対応も試してしまった。
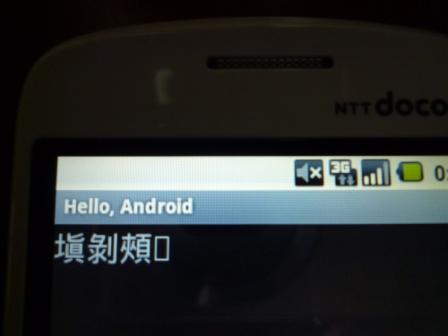
この結果は Android アプリケーションとしての出力だが、同様の文字列の Web ページをブラウザで表示させても同様だった。改定常用漢字表(試案)の中で、旧来の環境では特に問題が生じる字体「塡」「剝」「頰」「𠮟」のうち、やはり「𠮟」(くちへんに「七」)だけは表示されない、ということだ。
ただし、Android プラットフォームとしては Unicode の4バイト領域を処理できていて、Android 用の日本語フォントが「𠮟」(くちへんに「七」)に未対応なため、このような表示となっているのではないかと予想する。Android の C/C++ ではワイド文字型の wchar_t が4バイトなのだそうで、Google Groupのandroid-ndkでも驚きを伴う話題になっていたようだ。今後 Google はそれをサポートせず、代わりに ICU (International Components for Unicode) を使用するとのことである(日本Androidの会でのTetsuyuki Kobayashi さんの投稿より)。この ICU はもちろん Unicode の4バイト領域を処理できるコンポーネントである。
Android のフォントについて検索してみると、mashabow さんという方のブログ記事「16000字超の漢字と11000字超のハングルが入った軽量CJKフォント Droid Sans Fallback」を見つけた。Android 用のフォントは Ascender Corporation が開発、提供していて、この記事が書かれた2009年2月時点では Droid Sans Fallback (DroidSansFallback.ttf) というフォントで日本語がサポートされていた。しかしその漢字サポートの範囲は、"GB2312, Big 5, JIS 0208 and KSC 5601" (2007年11月の同社のプレスリリース "Ascender creates the new Droid font collection for Open Handset Alliance's Android platform" より) であって、中国語や韓国語も表示可能な一方で、JIS X 0213 は未対応ということになる。
そして、旧来の文字コード(JIS X 0208)と Unicode とのマッピングで問題となる漢字が先の4字(「塡」「剝」「頰」「𠮟」)なのだが、Unihan Database Lookup によると、「塡」は韓国語(KSC 5601、現在の KS X 1001)、「剝」「頰」は韓国語と繁体字中国語(Big 5)で対応しており、残るは結局「𠮟」(くちへんに「七」)ということになる。それゆえ先の写真で示したような状況となっていると推測する。
なお mashabow さんの記事では「もちろん、ひらがな・カタカナもちゃんと収録されているが、デザインが若干ぎこちない。おそらくは華康ゴシック体のかなと同じもの。また、漢字の筆画処理が大陸風なので、日本語の表示には難があるかもしれない。」としているが、現在では Droid Sans Japanese (DroidSansJapanese.ttf) という日本語向けフォントが用意されている。Android 開発環境(Android SDK)を確認してみると、Android 1.5 と 2.0 には含まれていないが、Android 1.6、2.0.1 と 2.1 には搭載されている。購入時は Android 1.5 を搭載している HT-03A でも日本語向けフォントぐらいは先行搭載していただろうし、購入後すぐに 1.6 (2009年10月配信開始)へのアップデートが起動するので、いずれにせよ現在では日本語風の書体を利用できる。今年相次いで発売される予定の Android 携帯は、おそらくその点については心配ないだろう。
とはいえ、つい数日前にリリースされた最新の Android 2.1 でも、DroidSansJapanese.ttf のファイルサイズ(1,173,140 バイト)に変化はない。Android SDK のエミュレータ (AVD) で先のアプリケーションをテストしても結果は変わらなかった。安岡孝一さんのブログ記事「【改定常用漢字表試案への意見】テンプレート」で列挙されている漢字に対象を拡大し、エミュレータ上でテストした結果は、下のような感じである。
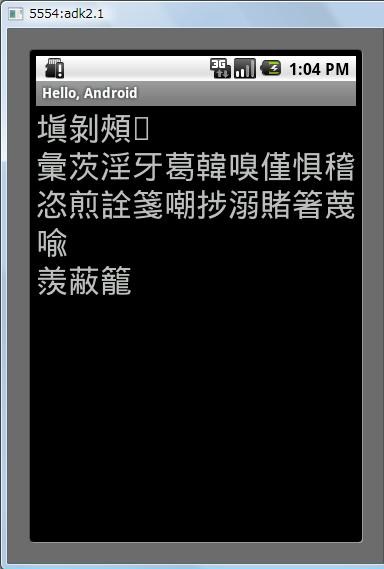
他の携帯電話や Windows XP ともまた違う結果なのだが、要するに JIS X 0213 にはまだ対応していない。今月 Google が発売した Nexus One (Android 2.1 搭載)でもおそらく同様で、「𠮟」(くちへんに「七」)は表示できないだろう。ソニーエリクソン、シャープ、NEC 等、日本のメーカーが今年発売予定の Android 携帯は、果たしてどうだろうか?
最近のコメント